前言
- 在文章中,我們會介紹與示範MySQL資料庫中,如何改善新增資料的速度
- 並對照改善前與改善後的速度做一個比較的結果
前置環境
- Ubuntu 16.04
- MySQL 5.7版本
MySQL資料庫引擎介紹
在討論增加資料速度之前,需要先探討MySQL兩個常用的資料庫引擎,因為選擇不同的資料庫引擎,在新增資料的速度上也是會有差異的。
MyISAM
- 此資料庫引擎簡易的設計與使用,給入門MySQL的人好使用
- 在查詢速度上會比InnoDB快
- 可以支援全文字搜尋,像是 …..WHERE column_name LIKE ‘%full_text_search%’
- 這個特性在5.6以後,InnoDB已經有支援了
- 使用的硬碟量大小會比InnoDB小,因為MyISAM會針對資料量的大小進行壓縮
MyISAM限制
- 沒有外來鍵(foreign keys)的支援
- 沒有交易(transaction)的機制可以使用
- 每一個資料表最多只有有64個索引(index)
- 每個資料表最大大小上限為 256TB
InnoDB
- 有支援交易機制(transaction)
- Row-level table locking 資料表鎖定
- 這裡鎖定指的是,在寫入資料的同時,有使用者做查詢的動作。
- 在InnoDB上來說,遭遇到上述的狀況,查詢速度並不會慢到哪裡去。
- 但在MyISAM上遇到上述情形的話,會從本來同一個SQL查詢時間只要0.01秒,變成要3秒
- 支援外來鍵(foreign keys)
- MyISAM相關特性較少會增加,日後版本(MySQL 8.0)上,增加相關新特性都會以InnoDB為主
InnoDB限制
- 沒有全文搜尋(前面有提過),但在MySQL 5.6版本以後就沒有這個問題
- 資料量無法有效的壓縮,在MySQL 5.5之後有ROW_FORMAT=COMPRESSED可以設定
- 資料表最大到64TB儲存(取決於InnoDB page size)
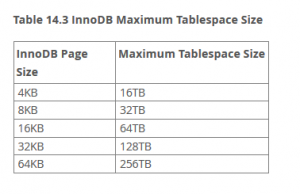
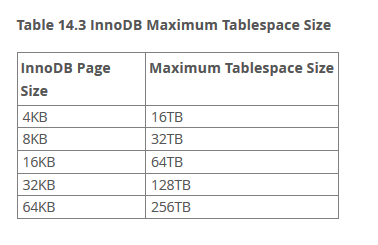
資料庫引擎的選擇方向與重點
- 以我們所需要儲存的電量資料來說
- 用MyISAM要承受的缺點
- 在寫入資料表的時候會鎖定(lock),導致在這同時查詢的速度會變慢(Table locking)
- 似乎無法做Cluster等分散式資料庫,在MySQL官網中只有提及InnoDB與NDB
- 只可以做Replication master-slave主從架構
- 可以選擇MyISAM的原因是
- 如果大部分時間都是用來讀取電量資料,效能會更好
- 在此電量資料中,沒有transaction需求
- 也沒有外來鍵需求
- 資料量大小較小,有壓縮過
- 用MyISAM要承受的缺點
- 如下圖顯示,我們可以知道,在資料數一樣多的情況下,MyISAM大小比InnoDB小

插入資料步驟
- 連接到資料庫server
- 傳送SQL查詢給server
- server解析SQL query
- 插入一筆(row) (1 x size of row)
- 插入索引(indexes) (1 x number of indexes)
- 關閉server
- 因為每次的插入資料,都會重複上述一系列的動作,那在打開資料表會造成overhead
- 資料在插入的時候,會一併插入定義的索引,因此每次插入一筆資料的時候會變慢。(假設index是使用B-tree indexes)
插入資料效能改善
- 首先,我們先讓bulk_insert_buffer_size設定成較高的大小
- 用LOAD DATA載入檔案方式取代INSERT,原因是因為用INSERT寫入資料表會較慢
- 在輸入資料的資料表中,若有欄位有設定預設值,若不需要改變預設值的情況下,不要設定值給此欄位,這樣會增加插入資料的速度
bulk_insert_buffer_size的修改

如上附圖可以知道此設定的相關資訊,下面有幾點此設定的特性。
- 若資料表使用的引擎為MyISAM的話,在加入資料時候,它會使用特別的類似像樹概念快取讓區塊插入資料更快。這會影響到INSERT與LOAD DATA
- 這個設定的值限制取決於在每一個位元下與thread,快取樹大小
- 設定0則關閉這個優化,預設設定值為:8 MB
bulk_insert_buffer_size設定
如下的SQL指令可以設定此bulk_insert_buffer_size值
- SET GLOBAL bulk_insert_buffer_size = 1024 * 1024 * 256
- 這意思是將bulk_insert_buffer_size設定成:256 MB
MyISAM插入資料優化
- 把bulk_insert_buffer_size設定成256 MB
- 寫入2億筆用電量資料
- 原本時間:2天左右
- 設定後:5小時
- 寫入2億筆用電量資料
InnoDB插入資料優化
- 把bulk_insert_buffer_size設定成256 MB
- 寫入2億筆用電量資料
- 原本時間:2天左右
- 設定後:約1天左右
- 寫入2億筆用電量資料
因為InnoDB所支援的特性較多,因此需要將transaction commit,UNIQUE檢查與foreign key檢查關閉之後,再寫入資料會加速插入資料的時間。
關閉transaction auto commit check
set autocommit=0; SQL query statement; commit;
關閉unique checks
set unique_checks=0; SQL query statement; set unique_checks=1;
關閉foreign key checks
set foreign_key_checks=0; SQL query statement; set foreign_key_checks=1;
LOAD DATA使用方式
如下是使用LOAD DATA方式將用電量的CSV檔案匯入到資料表裡面
資料表的綱要如下:
| 欄位名稱 | 欄位型態 | 編碼與排序 |
|---|---|---|
| electricID | VARCHAR(15) | utf8mb4_unicode_ci |
| date | datetime | 無 |
| mwh | double | 無 |
LOAD DATA相關SQL語法如下:
LOAD DATA LOCAL INFILE '/path/to/electric_data.csv' INTO TABLE electric_data_table FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS;
由上述的SQL插入資料語法,我們可以得到如下的資訊:
- 指定本地端的CSV檔,有指定的路徑
- 並指定寫入的資料表
- 每個欄位之間設定以逗號「,」隔開
- 每個封閉的欄位使用「”」隔開
- 這個意思是,因為有一些欄位中的值會包含「,」,為了要避免解析的錯誤,我們通常會將此資料的值用「”」括起來,這樣的話在解析時候這個值就會成功的解析出來
- 舉例來說,有一行(row)資料為:fields,”this is for enclosed fields,”,value
- 有設定enclosed by ‘”‘的話,這個「this is for enclosed fields,」就會當成一個這個欄位的值解析出來了
- 每一行斷行的字元為「\n」
- 忽略第一行,這可以取決於CSV檔案內容,因為有一些CSV檔案內容第一行為欄位名稱,我們需要將它省略掉,因為此欄位名稱不需要進入到資料表中
結論
| 評估項目名稱 | MyISAM | InnoDB |
|---|---|---|
| 需要全文字搜尋 (full-text search) | Yes | 5.6.4開始支援 |
| 需要交易 (transactions) | Yes | |
| 需要頻繁的查詢 (frequent select queries) | Yes | |
| 需要頻繁的新增,修改與刪除 (frequent select, insert,update) | Yes | |
| 需要資料表在插入同時,也有良好的查詢效果 | Yes | |
| 需要關聯式資料表設計 (foreign keys等) | Yes |
- 如果有頻繁的讀取,沒有頻繁的新增,修改與刪除→MyISAM
- 若使用MySQL版本比5.6還舊且需要full text search→MyISAM
參考資料
- https://dev.mysql.com/doc/refman/5.7/en/innodb-row-format.html
- https://gist.github.com/peter279k/225b7b4803b4f80400840777ed1583a3