前言
最近因緣際會之下,有一個與能源相關的研究案,需要處理將近2億筆的資料,如果只做到用SQL做查詢的時候,把常搜尋的欄位加入index索引,或是避免一些欄位重複,加入的主鍵primary key。
上述這些方式在資料量大的時候,容易產生一些瓶頸,因為利用BTree概念所作的索引是有搜尋的極限。
為了增加查詢的速度,我們可以考慮的方式如下:
- 依照年度劃分出個別的資料表
- 每個年度的資料表用月份為單位劃分成多個分區,總計是12個分區
分區的好處如下:
- 在資料表中做查詢的時候,可以指定分區,那只會找指定分區中的資料,而不會整張資料表做查詢,進而加快查詢的速度
- 在分區資料表中,可以允許我們指定那個分區進行刪除資料的動作
- 從MySQL 5.6之後,可以允許我們指定一個或多個分區中找尋我們要的資料
- 使用了分區之後,也會影響對資料修改相關的SQL語法,包含: DELETE, INSERT, REPLACE, UPDATE, and LOAD DATA, LOAD XML等
本文章,利用MySQL上面的分區功能實踐查詢的速度。
分區種類介紹
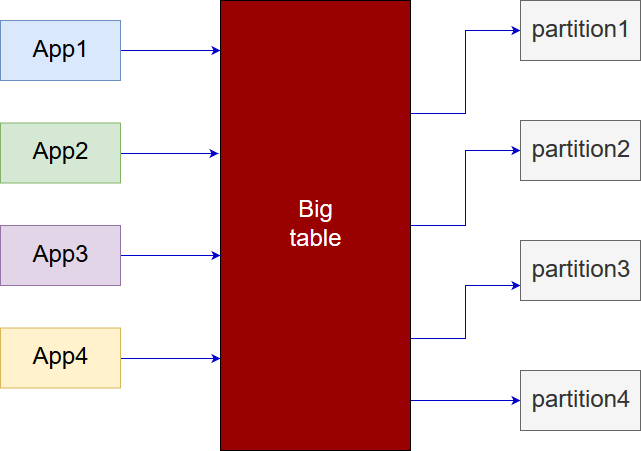
在講分區之前,我們可以從上面的示意圖知道,分區可以在Web應用程式在存取某個大張資料表的時候,先利用分區進行找尋範圍縮小的功能,接著在從指定的分區中尋找我們要的資料出來。分區的方式種類如下:
RANGE Partitioning
範圍分區,指的是自己定義某一個欄位,像是日期這種,就可以定義範圍做分區。
比如說,我們有一個2018 年整年的電量資料表叫做electric,裡面有電號,測量時間,測量的值等。所以依照敘述,我們可以建立出下面的資料表:
CREATE TABLE `electric_data_2018` ( `electricID` varchar(15) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '電號', `date` datetime NOT NULL COMMENT '當下測量用電時間', `mwh` double DEFAULT NULL COMMENT '用電量,單位wh' ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='1000戶各用戶各時段用電量';
那我們可以利用測量的時間做分區,分區呈現的方式如下12個分區:
- 2018-01-01到2018-01-31,即是「小於」2018-02-01 00:00:00
- 2018-02-01到2018-02-28,即是「小於」2018-03-01 00:00:00
- 2018-03-01到2018-03-31,即是「小於」2018-04-01 00:00:00
- 2018-04-01到2018-04-30,即是「小於」2018-05-01 00:00:00
- 2018-05-01到2018-05-31,即是「小於」2018-06-01 00:00:00
- 2018-06-01到2018-06-30,即是「小於」2018-07-01 00:00:00
- 2018-07-01到2018-07-31,即是「小於」2018-08-01 00:00:00
- 2018-08-01到2018-08-31,即是「小於」2018-09-01 00:00:00
- 2018-09-01到2018-09-30,即是「小於」2018-10-01 00:00:00
- 2018-10-01到2018-10-31,即是「小於」2018-11-01 00:00:00
- 2018-11-01到2018-11-30,即是「小於」2018-12-01 00:00:00
- 2018-12-01到2018-12-31,即是「小於」2019-01-01 00:00:00
那以SQL方式建立帶有分區資料表方式如下:
ALTER TABLE `electric_data_2018`
PARTITION BY RANGE (TO_DAYS(`date`))
(
PARTITION p_201802 VALUES LESS THAN (TO_DAYS('2018-02-01 00:00:00')),
PARTITION p_201803 VALUES LESS THAN (TO_DAYS('2018-03-01 00:00:00')),
PARTITION p_201804 VALUES LESS THAN (TO_DAYS('2018-04-01 00:00:00')),
PARTITION p_201805 VALUES LESS THAN (TO_DAYS('2018-05-01 00:00:00')),
PARTITION p_201806 VALUES LESS THAN (TO_DAYS('2018-06-01 00:00:00')),
PARTITION p_201807 VALUES LESS THAN (TO_DAYS('2018-07-01 00:00:00')),
PARTITION p_201808 VALUES LESS THAN (TO_DAYS('2018-08-01 00:00:00')),
PARTITION p_201809 VALUES LESS THAN (TO_DAYS('2018-09-01 00:00:00')),
PARTITION p_201810 VALUES LESS THAN (TO_DAYS('2018-10-01 00:00:00')),
PARTITION p_201811 VALUES LESS THAN (TO_DAYS('2018-11-01 00:00:00')),
PARTITION p_201812 VALUES LESS THAN (TO_DAYS('2018-12-01 00:00:00')),
PARTITION p_201901 VALUES LESS THAN (TO_DAYS('2019-01-01 00:00:00')),
PARTITION p_max_future_dates VALUES LESS THAN MAXVALUE
);
- 上述建立分區的意思就是,把「測量日期」欄位轉變成距離year 0有多少天數,將日期轉變成數字之後,我們就可以利用這個天數來進行所謂範圍分區的動作。
- 其中,…..LESS THAN…..就是小於的意思,舉例來說,第一個分區指的是1月所有電量資料,則小於「2018-02-01 00:00:00」即是這個意思。
- 當然,只要可以將天數轉換成數字當作範圍,都可以用來進行範圍分區,所以我們也可以轉換成UNIX TIMESTAMP的值做範圍分區。相關建立此分區方式如下:
ALTER TABLE `electric_data_2018`
PARTITION BY RANGE (UNIX_TIMESTAMP(`date`))
(
PARTITION p_201802 VALUES LESS THAN (UNIX_TIMESTAMP('2018-02-01 00:00:00')),
PARTITION p_201803 VALUES LESS THAN (UNIX_TIMESTAMP('2018-03-01 00:00:00')),
PARTITION p_201804 VALUES LESS THAN (UNIX_TIMESTAMP('2018-04-01 00:00:00')),
PARTITION p_201805 VALUES LESS THAN (UNIX_TIMESTAMP('2018-05-01 00:00:00')),
PARTITION p_201806 VALUES LESS THAN (UNIX_TIMESTAMP('2018-06-01 00:00:00')),
PARTITION p_201807 VALUES LESS THAN (UNIX_TIMESTAMP('2018-07-01 00:00:00')),
PARTITION p_201808 VALUES LESS THAN (UNIX_TIMESTAMP('2018-08-01 00:00:00')),
PARTITION p_201809 VALUES LESS THAN (UNIX_TIMESTAMP('2018-09-01 00:00:00')),
PARTITION p_201810 VALUES LESS THAN (UNIX_TIMESTAMP('2018-10-01 00:00:00')),
PARTITION p_201811 VALUES LESS THAN (UNIX_TIMESTAMP('2018-11-01 00:00:00')),
PARTITION p_201812 VALUES LESS THAN (UNIX_TIMESTAMP('2018-12-01 00:00:00')),
PARTITION p_201901 VALUES LESS THAN (UNIX_TIMESTAMP('2019-01-01 00:00:00')),
PARTITION p_max_future_dates VALUES LESS THAN MAXVALUE
);
若我們要看所有分區名稱在此資料表的資訊,我們可以使用下列的SQL做到。
SELECT PARTITION_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME='electric_data_2018';
當然,範圍分區也可以用在數值,比如說,我們可以利用用電量「mwh」這個欄位,將數值區分成下列幾塊:
- partition p0 ( mwh < 100 )
- partition p1 ( mwh < 500 )
- partition p2 ( mwh <1000 )
- partition p3 ( mwh <1500 )
相關SQL語法就會變成:
ALTER TABLE `electric_data_2018` PARTITION BY RANGE (`mwh`) ( PARTITION p0 VALUES LESS THAN (100), PARTITION p1 VALUES LESS THAN (500), PARTITION p2 VALUES LESS THAN (1000), PARTITION p3 VALUES LESS THAN (1500) );
若我們想要刪除某一個分區,我們可以使用下列的SQL語法做到:
ALTER TABLE electric_data_2018 TRUNCATE PARTITION p0;
LIST Partitioning
清單分區,指的是,假設一張資料表,已經有一個預設的集合,假設如下:
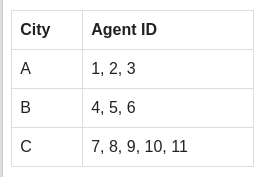
上述表格意思是:
- 有一個欄位叫做「agent_code」表示這三個城市的代碼
- City A代碼是1,2,3
- City B代碼是4,5,6
- City B代碼是7,8,9,10,11
那用LIST分區所建立SQL語法如下:
CREATE TABLE sale_mast2 (bill_no INT NOT NULL, bill_date TIMESTAMP NOT NULL, agent_codE INT NOT NULL, amount INT NOT NULL) PARTITION BY LIST(agent_code) ( PARTITION pA VALUES IN (1,2,3), PARTITION pB VALUES IN (4,5,6), PARTITION pC VALUES IN (7,8,9,10,11));
意思是:
- 將欄位「agent_code」城市代碼當作LIST分區
- 若代碼1,2,3的放在pA分區名稱中,亦即City A
- 若代碼4,5,6的方在pB分區中,亦即City B
- 若代碼7,8,9,10,11放在pC分區中,亦即City C
由上述的分區概念,我們可以知道幾件事情:
- 使用LIST做分區是指的是那個欄位可以分類成不同的種類/集合
COLUMNS Partitioning
以欄位名稱做分區,指的是,將一組欄位並將裡面的值當作範圍或是集合進行分區的概念,那又可以分成:
- RANGE COLUMN Partitioning
- LIST COLUMN Partitioning
RANGE COLUMN Partitioning
我們可以直接看下列的SQL語法範例:
CREATE TABLE table3 (col1 INT, col2 INT, col3 CHAR(5), col4 INT) PARTITION BY RANGE COLUMNS(col1, col2, col3) (PARTITION p0 VALUES LESS THAN (50, 100, 'aaaaa'), PARTITION p1 VALUES LESS THAN (100,200,'bbbbb'), PARTITION p2 VALUES LESS THAN (150,300,'ccccc'), PARTITION p3 VALUES LESS THAN (MAXVALUE, MAXVALUE, MAXVALUE));
- 我們建立一個資料表叫做「table3」,而裡面的欄位分別有:「col1」,「col2」,「col3」與「col4」
- 前三個欄位分別依序排列成col1, col2, clo3並在每一個分區作為一組
- 每一個值列表使用定義好的條件進行用值當作範圍的分區
- 篩選的時候,裡面資料的欄位順序需要相同
LIST COLUMNS partitioning
跟先前的「list partitioning」有點類似,不過這是以「COLUMNS」欄位做它配的欄位列表分區。我們城市代碼列表如下:

我們可以從下面SQL語法知道:
CREATE TABLE salemast ( agent_id VARCHAR(15), agent_name VARCHAR(50),
agent_address VARCHAR(100), city_code VARCHAR(10))
PARTITION BY LIST COLUMNS(agent_id) (
PARTITION pcity_a VALUES IN('A1', 'A2', 'A3'),
PARTITION pcity_b VALUES IN('B1', 'B2', 'B3'),
PARTITION pcity_c VALUES IN ('C1', 'C2', 'C3', 'C4', 'C5'));
- 首先,先建立一個叫做「salemast」的資料表,欄位裡面包含了帳單ID,帳單的地址,名稱城市代碼等
- 建立三種不同的分區,每個分區分別代表三個城市,因為每一個城市代碼會有不同但是有類似,那就可以用這種方法,利用城市代碼用來「LIST COLUMN Partitioning」
除了使用欄位有城市代碼之外,也可以使用欄位有「DATE」或是「DATETIMESTAMP」的型別來做「LIST COLUMN Partitioning」分區
我們用上述的「electric_data_2018」資料表當作例子,那分區的定就可以改成:
ALTER TABLE `electric_data_2018`
PARTITION BY RANGE COLUMNS (`date`)
(
PARTITION p_201802 VALUES LESS THAN ('2018-02-01 00:00:00'),
PARTITION p_201803 VALUES LESS THAN ('2018-03-01 00:00:00'),
PARTITION p_201804 VALUES LESS THAN ('2018-04-01 00:00:00'),
PARTITION p_201805 VALUES LESS THAN ('2018-05-01 00:00:00'),
PARTITION p_201806 VALUES LESS THAN ('2018-06-01 00:00:00'),
PARTITION p_201807 VALUES LESS THAN ('2018-07-01 00:00:00'),
PARTITION p_201808 VALUES LESS THAN ('2018-08-01 00:00:00'),
PARTITION p_201809 VALUES LESS THAN ('2018-09-01 00:00:00'),
PARTITION p_201810 VALUES LESS THAN ('2018-10-01 00:00:00'),
PARTITION p_201811 VALUES LESS THAN ('2018-11-01 00:00:00'),
PARTITION p_201812 VALUES LESS THAN ('2018-12-01 00:00:00'),
PARTITION p_201901 VALUES LESS THAN ('2019-01-01 00:00:00')
);
上述的分區方式就是指:
- 利用「date」欄位是「datetime」型別,並用LIST COLUMN分區中的「RANGE COLUMN」分區
- 分區就是「RANGE BY COLUMN」,並以月份做分區,總共分成12個月
HASH Partitioning
HASH分區指的是,利用某一個欄位,把它做內建的MySQL HASH雜湊之後得到的結果,並指定分區個數讓MySQL進行預先分區的動作。SQL範例如下:
CREATE TABLE student (student_id INT NOT NULL, class VARCHAR(8), name VARCHAR(40), date_of_admission DATE NOT NULL DEFAULT '2000-01-01') PARTITION BY HASH(student_id) PARTITIONS 4;
KEY Partitioning
此種分區方法是HASH分區中裡面的其中一種,主要是用來把主鍵或是設定UNIQUE唯一值的欄位拿去做雜湊之後並透過指定分區的數量分散到那些分區之中。SQL範例如下:
CREATE TABLE table1 ( id INT NOT NULL PRIMARY KEY, fname VARCHAR(25), lname VARCHAR(25)) PARTITION BY KEY() PARTITIONS 2;
CREATE TABLE table2 ( id INT NOT NULL, fname VARCHAR(25), lname VARCHAR(25), UNIQUE KEY (id)) PARTITION BY KEY() PARTITIONS 2;
Sub partitioning
子分區,就是把原先的第一層分區,再做細分下去。其SQL範例如下:
CREATE TABLE table10 (BILL_NO INT, sale_date DATE, cust_code VARCHAR(15), AMOUNT DECIMAL(8,2)) PARTITION BY RANGE(YEAR(sale_date) ) SUBPARTITION BY HASH(TO_DAYS(sale_date)) SUBPARTITIONS 4 ( PARTITION p0 VALUES LESS THAN (1990), PARTITION p1 VALUES LESS THAN (2000), PARTITION p2 VALUES LESS THAN (2010), PARTITION p3 VALUES LESS THAN MAXVALUE );
上述這個分區指的是:
- 先把銷售日期取得年份,當作第一層分區
- 接著,再第二層子分區為p0, p1, p2, p3並分成1990, 2000, 2010年份
- 所以這樣就會有4 * 4 = 16 個分區,即p0, p1, p2, p3各有4個分區
參考資料
- http://acmeextension.com/mysql-table-partitioning
- https://www.w3resource.com/mysql/mysql-partition.php
- https://www.w3schools.com/sql/func_mysql_to_days.asp