前言
這篇文章,是我在開發的資料視覺化系統的過程中,所猜測的資料庫結構,因為這個開發系統是這樣的:
- 資料視覺化系統由我們開發,資料庫以及資料來源的建置由另外一間案主請的外包公司負責
- 當初在開發的時候,我從專案經理得到的訊息為:之後他們資料庫所使用的是「PostgreSQL」,所以我在開發與測試環境中都使用此資料庫作為我們系統測試資料庫
- 在移入內部網路時候,才發現資料庫的架構之不對勁
本文章中,是在探討我在將系統移入的過程中,如何一步步的發現資料庫的架構
資料庫架構
原本一開始聽到的架構是,我以為是長這樣的

- 「1」的部份,我認為是我們系統透過PostgrSQL溝通,查詢我們要的資料
- 「2」的部份,我認為是有固定排程工作(?),Hadoop上的放在HDFS上的資料會匯入到PostgreSQL資料庫中
- 當初我聽到這樣資料庫的架構,我一直處在半信半疑的狀態,不過為了系統開發的時程,那時候也沒有想太多,就直接先按照這樣的架構去建立一個PostgrSQL來當作測試資料庫後開始開發系統了
後來,到後面的移入內網的時候,我慢慢從它們講的名詞猜出其實是長下面這樣子的架構。
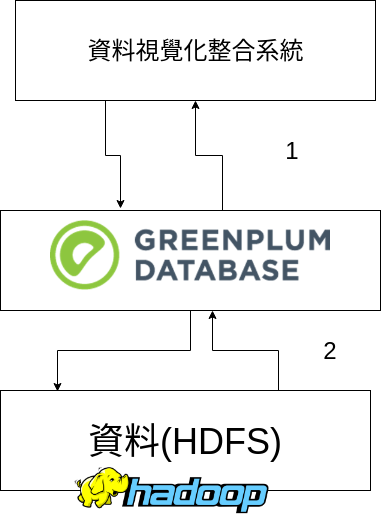
一開始我還猜資料(HDFS)部份有使用HBase,不過後來廠商說只使用HDFS。
其架構流程如下:
- 「1」的部份,就是我們系統會去向Greenplum資料庫請求我們要的資料
- 「2」的部份,則是我們Greenplum資料庫會向放在Hadoop的HDFS上的資料載入到資料表並做查詢
資料庫架構差異
這兩者其實有很大的差異,其差別如下:
- 我所想的是利用完全的PostgreSQL的所有特性,我們面對查詢的部份只有SQL查詢優化
- 廠商所設計的架構,是目的為了要讓存放在HDFS上面的檔案可以透過SQL方式查詢,因此使用了基於PostgreSQL所改良的資料庫,叫做Greenplum
- 透過此資料庫,可以建立外部資料表並指定HDFS上的檔案進行檔案的載入
Greenplum 資料庫建立外部資料表
本章節,就是在描述如何使用建立外部資料表來載入HDFS上的資料。
首先,先要了解,Greenplum 可以當作是一個查詢的介面,透過它去查詢資料。
並藉由此機制建立readable external table,可以讀取的協定如下:
- host file system檔案系統上的檔案
- an NFS server上的檔案 (NFS=Network file system)
- Hadoop file system (HDFS).
外部資料表(external table)相關介紹
從官方文件中可以得知,這類的external table有分成下列幾種
- CREATE EXTERNAL TABLE or CREATE EXTERNAL WEB TABLE
- 這類是建立一個readable可以讀取的外部資料表,通常是載入外部的儲存資料空間做使用
- 那也不能在此外部資料表上建立索引(indexes)
- UPDATE, INSERT, DELETE, or TRUNCATE 等操作都不被允許
- CREATE WRITABLE EXTERNAL TABLE or CREATE WRITABLE EXTERNAL WEB TABLE
- 這類是建立一個可寫入資料的外部資料表,通常是要載入外部資料庫之後,變成單獨的資料表且會存放在Greenplum資料庫中
- 此類型的外部資料表允許可以INSERT插入資料的動作
- SELECT, UPDATE, DELETE or TRUNCATE 等操作都不被允許
在Greenplum官方範例文件中,有如下的敘述:
假設我們有一個資料庫檔案,叫做 sales,分區資料表方式如下圖:
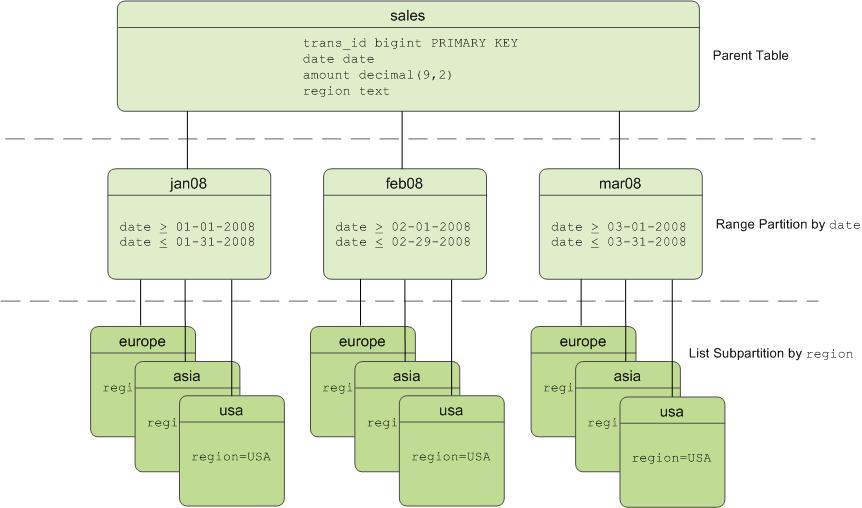
其分區資料表概念就是,有一個資料表是parent table,那依照以月分區的方式建立多個child tables
分區的方式如下:
- range partitioning: division of data based on a numerical range, such as date or price. (這個指的是利用某個欄位可以做日期範圍的分區,如此一來就可以)
- list partitioning: division of data based on a list of values, such as sales territory or product line. (列表分區,以銷售資料來說,就是可以用銷售資料的類型或是產品線種類進行分區)
Example Exchanging a Partition with an External Table
本章節,會以Greenplum官方文件做範例,透過官方提供的sales範例來呈現如何做到建立外部資料表並將它們做成分區,以及如何讀取它們。
從上面解釋外部資料表的不同類型,我們可以知道可寫跟可讀的資料表上的差異,那為了要讓資料表可以寫入資料與查詢,我們要做的建立外部資料表方式步驟如下:
首先,我們需要先建立一個名叫sales的資料表,其SQL語法如下:
CREATE TABLE sales (id int, year int, qtr int, day int, region text) DISTRIBUTED BY (id) PARTITION BY RANGE (year) ( PARTITION yr START (2010) END (2014) EVERY (1) ) ;
- 裡面包含了id, 年分, qtr 某個訊息的值, 日期以及地區
- 這裡分區的方式是用年份來區分,那在我們外包的資料庫廠商則是用日期(年月日)作為分區的範圍
- 分區會有一個範圍,則是起始與結束的年份,那用日期則是,開始日期到結束的日期,以上述的例子來說,就是建立2010到2013年份之間的sales資料
接著,要確定讀取外部資料的來源是存放在哪個地方,在此範例中,假設外部要存取的檔案是放在 gpfdist (Greenplum Parallel File Server)
接著先建立一個可以寫入的外部資料表,相關SQL語法如下:
CREATE WRITABLE EXTERNAL TABLE my_sales_ext ( LIKE sales_1_prt_yr_1 ) LOCATION ( 'gpfdist://gpdb_test/sales_2010' ) FORMAT 'csv' DISTRIBUTED BY (id) ;
接著在建立一個readable可以讀取的外部資料表
CREATE EXTERNAL TABLE sales_2010_ext ( LIKE sales_1_prt_yr_1) LOCATION ( 'gpfdist://gpdb_test/sales_2010' ) FORMAT 'csv' ;
接著從leaf child partition上的資料寫進先前步驟建立的external table中
INSERT INTO my_sales_ext SELECT * FROM sales_1_prt_yr_1 ;
接著把先前建立的external table與目前存在的leaf child partition table互相交換,相關SQL語法如下:
ALTER TABLE sales ALTER PARTITION yr_1 EXCHANGE PARTITION yr_1 WITH TABLE sales_2010_ext WITHOUT VALIDATION;
上面步驟做完之後,資料表就會變成:
- 原來external table sales_1_prt_yr_1 就會變成 leaf child partition table
- 原本的leaf child partition table sales_2010_ext就會變成 external table
接著把sales_2010_ext資料表,因為交喚之後,我們不需要external table了,所以可以把它移除。
DROP TABLE sales_2010_ext ;
接著我們把分區名稱,做一個修改,因為本來,分區名稱在建立sales資料表的時候是下列的分區名稱:
- yr_1
- yr_2
- yr_3
- yr_4
那也可以透過更改分區名稱,把 sales_1_prt_yr_1 資料表標註成這是一個external table,那這是一個可選的工作。相關語法如下:
ALTER TABLE sales RENAME PARTITION yr_1 TO yr_1_ext ;
讀取外部資料
從上述的章節,我們可以初步的知道如何建立外部資料表載入外部檔案並成為分區資料表的方式。那如果是要載入其他檔案系統上的檔案呢?
我們可以以廠商使用的HDFS為例:
在官方文件中,Greenplum 5.2.0版本時候,gphdfs已經廢棄了,這是一個Greenplum設計的協定,並專門去讀取在HDFS上的檔案用的。
官方強烈建議使用它們設計的另一個協定,叫做PXF (The Greenplum Platform Extension Framework),這是一個Greenplum所設計的統一介面協定。
所以建立外部資料表方式就可以改成:
CREATE EXTERNAL TABLE pxf_hdfs_text(location text, month text, num_orders int, total_sales float8)
LOCATION ('pxf://data/pxf_examples/pxf_hdfs_simple.txt?PROFILE=hdfs:text')
FORMAT 'TEXT' (delimiter=E',');
CSV 檔,也可以使用上述的SQL語法去建立相關的資料表
結論
- 開發的系統與資料庫分開給不同的人做,讓我感覺就是在一開始的時候,就要知道對方確切的資料庫架構會長什麼樣子,以便日後開發系統上的順利。
而不是等到系統已經完成,進入維護的時候,我才發現資料庫的架構是長這個樣子。要再去改動SQL查詢的時候的成本就會變得很高。 - 一個專案經理懂不懂技術,就可以從一個案子知道。
因為當初我所聽到的架構與我和廠商DBA做完溝通之後,完全想到跟猜測的根本是不一樣的東西。 - 這種資料庫架構來說,不能說是不好,這是一個可以用SQL上讀取放在HDFS或是其他檔案系統上的檔案,這樣的方式也是讓其他人能夠較輕易的讀取Haddop HDFS 上的檔案。
參考資料
- NFS
- https://gpdb.docs.pivotal.io/5200/pxf/access_hdfs.html
- https://gpdb.docs.pivotal.io/5200/pxf/hdfs_text.html#profile_text
- http://docs.greenplum.org/5160/admin_guide/ddl/ddl-partition.html#topic_yhz_gpn_qs
- 「Exchanging a Leaf Child Partition with an External Table」之章節
- https://gpdb.docs.pivotal.io/5200/admin_guide/external/g-working-with-file-based-ext-tables.html
- https://gpdb.docs.pivotal.io/560/ref_guide/sql_commands/CREATE_EXTERNAL_TABLE.html