前言
因為工作上的需要,需要建置HBase當做資料儲存的空間,而這個同樣也是一個No-SQL資料庫。至於什麼是No-SQL DB,則不在此文章的範圍內,可以自行去查詢了解。
在本篇文章中,會教導該如何在Ubuntu 16.04中,將Hadoop與HBase架設起來。
前置環境
下面則是列出所需要的環境。
- 一台乾淨且裝有Ubuntu 16.04的主機
安裝Hadoop
在本章節中,教導使用者們一步一步的安裝好Hadoop,可能在這裡會問:我只需要HBase,但是一定要安裝Hadoop嘛?答案是肯定的,因為HBase這個資料庫是相依於Hadoop,因此需要先安裝好Hadoop,才可以安裝HBase。
第一步:登入主機
首先先使用ssh登入到我們的主機
ssh user-name@ip-address-or-domain-name
第二步:建立hadoop使用者
在建立Hadoop之前,需要先建立一個名為hadoop使用者給Hadoop使用。先使用下面指令建立一個使用者。
sudo useradd -m hadoop -s /bin/bash
接著為這個hadoop使用者設置一個密碼,注意:密碼會需要輸入兩次來做確認
sudo passwd hadoop
為了增加目錄權限操作方便,我們將hadoop這個使用者設定有root權限可以使用,設定方式如下指令:
sudo adduser hadoop sudo
到這裡,就把Hadoop需要的使用者建立完成了,記得使用下面指令切換使用者再進行下一步!
su hadoop
第三步:更新鏡像來源並安裝JAVA環境
在Ubuntu底下,安裝任何的套件前,我們都會使用下面的指令先更新好鏡像來源網址。
sudo apt-get update sudo apt-get install default-jdk default-jre
安裝好JAVA環境之後,可以使用下面的指令做測試:
java -version
如下圖所示:
![]()
第四步:設定JAVA環境執行路徑
在本步驟中,需要設定JAVA_HOME環境變數。
先編輯在家目錄下面的.bashrc檔案。
vim ~/.bashrc
接著加入路徑,注意:路徑有可能不同,需要自己設定正確的相對應路徑
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export PATH=$PATH:$JAVA_HOME/bin
# 設定後面所需要用到的Hadoop相關執行路徑 export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
設定完成之後,再執行source指令將此環境變數載入。
source ~/.bashrc
接著可以使用,whereis java與java -version這兩個指令做驗證。
whereis java java -version
其結果如下圖所示:
![]()
第五步:安裝Hadoop
我們這邊選用的是2.8.5的版本,使用wget指令來進行下載壓縮檔。
wget http://apache.mirror.gtcomm.net/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
第六步
- 解壓縮Hadoop壓縮檔到/usr/local資料夾
- 切換資料夾至/usr/local
- 將資料夾名稱重新命名
- 將/usr/local/hadoop切換權限給hadoop使用者
sudo tar -zxf ~/hadoop-2.8.5.tar.gz cd /usr/local sudo mv ~/hadoop-2.8.5/ ./hadoop sudo chown -R hadoop /usr/local/hadoop
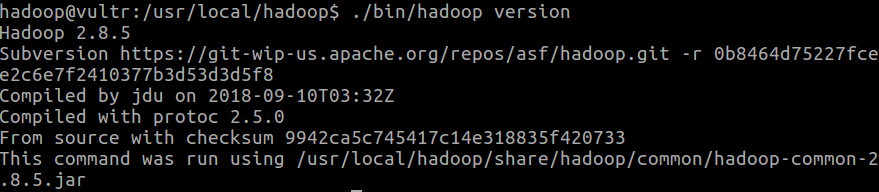
第七步:驗證Hadoop是否可以運行
下面指令可以幫助我們驗證hadoop是否可以正常運行
cd /usr/local/hadoop ./bin/hadoop version
如果可以成功運行的話,如下面截圖所示:
第八步:偽分佈式Hadoop
Hadoop允許可以使用兩個分離的process運行,意思就是一個當NameNode一個當DataNode,同時讀取的是HDFS文件。
要修改成此模式需要修改core-site.xml與hdfs-site.xml這兩個設定檔案。
Hadoop設定文件是以XML格式,每個設定的property都有起始與結尾標籤,在標籤裡面放置的是設定值。
先開啟,core-site.xml檔案。
cd /usr/local/hadoop vim ./etc/hadoop/core-site.xml
接著在<configuration></configuration>標籤之間插入下面的值。
<property> <name>hadoop.tmp.dir</name> <value>file:///usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property>
接著,修改hdfs-site.xml設定檔案
cd /usr/local/hadoop vim ./etc/hadoop/hdfs-site.xml
一樣在<configuration>與</configuration>中加入:
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/local/hadoop/tmp/dfs/data</value> </property>
設定完成後,接著就可以使用下面指令執行NameNode初始化。
cd /usr/local/hadoop ./bin/hdfs namenode -format
執行完成之後,可以注意到這兩行,若是一樣,則代表執行成功。

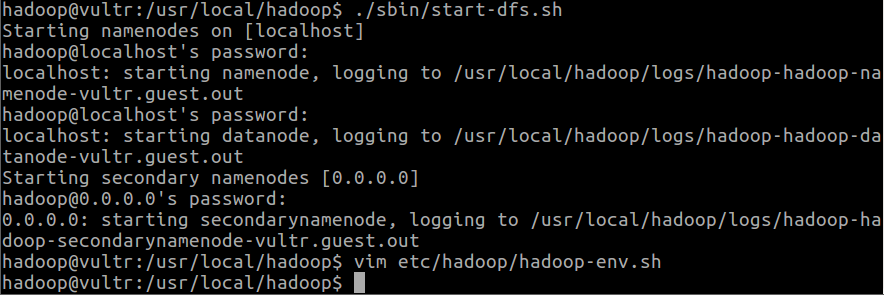
第九步:執行NameNode與DataNode process
使用下面的指令執行與啟動NameNode與DataNode process
cd /usr/local/hadoop ./sbin/start-dfs.sh
執行此process期間,會使用到ssh相關的登入,因次遇到yes就輸入yes。
遇到打密碼,就打hadoop使用者的密碼。
若在執行過程中出現「localhost: Error: JAVA_HOME is not set and could not be found.」等字樣,則需要在/usr/local/hadoop/etc/hadoop/hadoop-env.sh 底下設定JAVA_HOME環境變數
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
設定完成之後,再執行一次:./sbin/start-dfs.sh就會成功了。其成功截圖畫面如下:
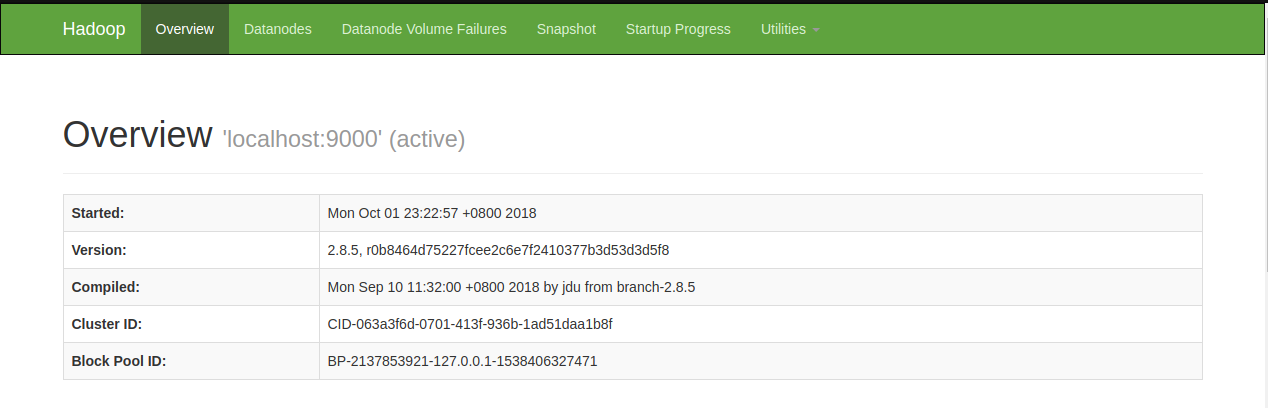
設定好之後,使用網路瀏覽器拜訪網址:http://ip-address-or-domain-name:50070,就可以看到運行的狀態頁面了。
第十步:啟動yarn
首先,先執行下面的指令,修改檔案名稱並進行mapred-site.xml編輯。
cd /usr/local/hadoop mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml vim ./etc/hadoop/mapred-site.xml
接著在<configuration>與</configuration>中加入下面的設定標籤。
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
接著設定yarn-site.xml設定檔。
cd /usr/local/hadoop vim ./etc/hadoop/yarn-site.xml
在<configuration>與</configuration>標籤中加入下面的設定值。
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
接著就可以啟動yarn了。當然,中間會打密碼執行。
執行下面指令來啟動,啟動完成之後,可以拜訪:http://ip-address-or-domain-name:8088/cluster來看目前所有的叢集(cluster)的狀態與資訊。
cd /usr/local/hadoop ./sbin/start-yarn.sh # 啟動背景 web server 查看歷史運作紀錄 ./sbin/mr-jobhistory-daemon.sh start historyserver

後記
- 如果使用較低方案的VPS 方案做練習的話,會跑不起來,原因是因為RAM太小不夠。因此需要使用與這篇文章來設定swap來達到這個目的。
- 有的時候ssh連線是使用非port number 22,因此需要使用到HADOOP_SSH_OPTS來設定port number。設定此環境變數在.bashrc檔案即可,記得使用source 重新載入此檔案。設定環境變數如下,22是我們可以修改的port number:
export HADOOP_SSH_OPTS="-p 22"
參考資料
- how-to-install-java-with-apt-get-on-ubuntu-16-04
- Hbase installation on ubuntu
- Ubuntu-16-04上安装Hadoop并成功运行
下一篇將介紹如何安裝:HBase